{kind=link}
Introduction
If you want to teach a computer to see, you meet CNNs. I will explain cnn architecture in simple language. This guide keeps sentences short and clear. I wrote it like a friendly chat with examples. You will learn what parts make a cnn architecture work. You will see why convolution, pooling, and normalization matter. I add practical tips from projects I tried. I include classic models like AlexNet and ResNet as examples. You will also find how to design or reuse a cnn architecture. The goal is clear learning for any reader. Let’s start with the big idea and then move step by step.
What is a CNN architecture?
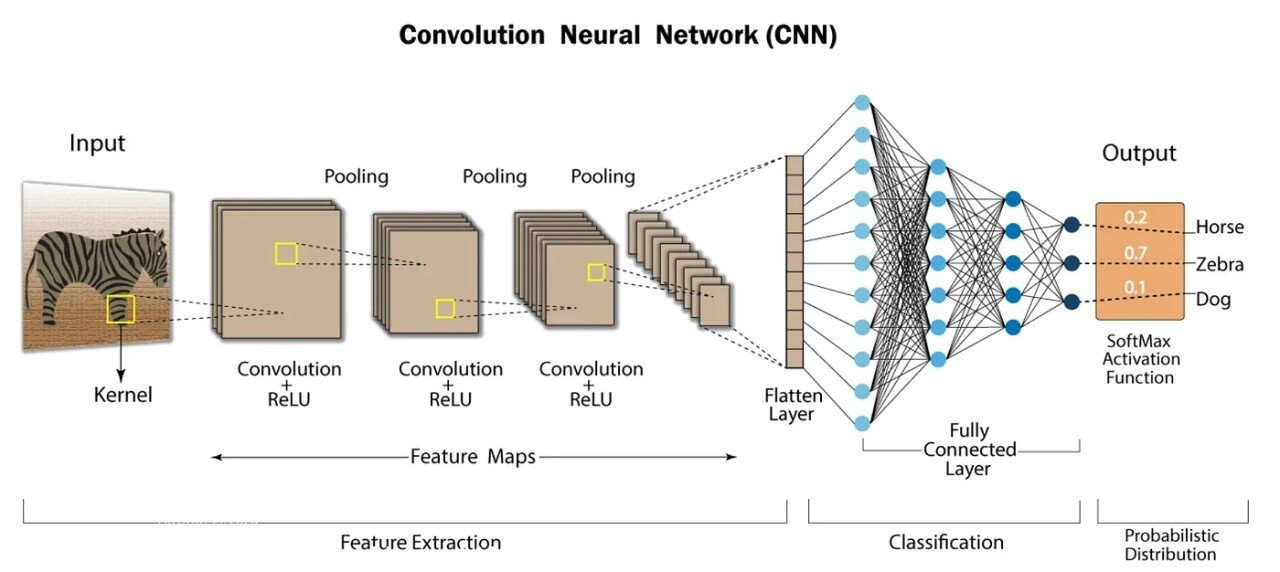
A cnn architecture is a family of deep learning models for images. It uses convolution to find patterns in images. The model learns filters or kernels automatically from data. Each layer builds more complex visual features than the last. Early layers see edges and textures. Later layers see faces, objects, or whole scenes. A cnn architecture usually stacks convolution, activation, and pooling layers. It often ends with fully connected layers or global pooling. People use these models for image classification, detection, and segmentation. The design choices of layers shape performance and speed. That is the core idea behind modern visual AI systems.
The convolutional layer explained
Convolutional layers are the engine of a cnn architecture. They use small filters to scan the image. Each filter produces a feature map when sliding over pixels. Filters capture edges, textures, or repeated patterns. The stride controls how the filter moves across the image. Padding decides if edges are preserved or trimmed. Stacking many filters creates rich, layered representations. Training changes filter values to match the task. Larger networks usually have more filters per layer. Convolution is efficient because it reuses weights in many places. This weight sharing helps the network generalize to new images.
Activation functions and non-linearity
After convolution, CNNs use activation functions to add non-linearity. ReLU is the most common activation in cnn architecture. ReLU sets negative values to zero. This keeps the model simple and fast. Other activations include Leaky ReLU, ELU, and GELU. They help when ReLU kills too many values. Non-linearity lets layers stack to learn complex mappings. Without activation, multiple layers would collapse into one linear transform. Choosing activation affects training speed and final accuracy. In practice, ReLU or a variant works well for most vision tasks.
Pooling layers: why and how
Pooling reduces the size of feature maps in a cnn architecture. Max pooling keeps the strongest signal in a region. Average pooling computes the mean value. Pooling increases the receptive field of later layers. It helps the model focus on important features. Pooling also reduces computation and memory needs. Global average pooling often replaces fully connected layers near the output. It reduces overfitting for many tasks. However, aggressive pooling can remove fine spatial details. For tasks like segmentation, less pooling or strided convolutions are often better. The right pooling choice depends on your problem.
Normalization, dropout, and regularization
Normalization stabilizes training in a cnn architecture. Batch Normalization is widely used. It normalizes layer activations per batch. This speeds up training and allows higher learning rates. LayerNorm and GroupNorm work better for some setups. Dropout randomly zeroes activations to reduce overfitting. Weight decay penalizes large weights during optimization. Data augmentation is another strong regularizer for images. Mixup and CutMix are modern augmentation tricks. Together, these techniques help models generalize to unseen images. Regularization choices change depending on your dataset size and noise.
Famous backbone designs: AlexNet, VGG, ResNet, and more
Historical models shaped modern cnn architecture. AlexNet in 2012 showed deep nets beat traditional methods. VGG used many simple stacked layers to improve results. ResNet introduced residual connections to let very deep nets train stably. Inception used mixed filter sizes in one block for efficiency. MobileNet and EfficientNet prioritized speed and compact size. Each backbone trades off accuracy, speed, and memory. Choosing a backbone depends on your hardware and task. For prototypes, use a small backbone. For research, try deeper or novel architectures.
Designing your own CNN architecture
Designing a cnn architecture starts with your goals. Ask about speed, memory, and accuracy first. Pick input size and how many classes you have. Start with a simple backbone and add layers slowly. Use small filters like 3×3 and stack them to increase depth. Add BatchNorm and ReLU after convolutions. Use pooling or strides to reduce resolution gradually. Consider residual or skip connections to ease training. Monitor training and validation loss for overfitting. Tune learning rate, batch size, and augmentations next. Iteration and measurement are key to good design.
Transfer learning and pretrained backbones
Transfer learning speeds progress with cnn architecture. You start from a model pretrained on a large dataset. Common pretrained datasets include ImageNet. The pretrained backbone already learned useful visual features. You then fine-tune the model on your smaller dataset. Often only the last layers need heavy retraining. This approach reduces the data and compute you need. It also helps models generalize better in low-data settings. For very similar tasks, freezing early layers works well. For different tasks, fine-tune more layers or the whole network.
Practical tips for training CNNs
Training a cnn architecture requires good data and settings. Use clear labels and clean images. Augment images with flips, crops, and color jitter. Start with a sane learning rate and reduce it on plateau. Use optimizers like Adam or SGD with momentum. Larger batch sizes need learning rate tuning. Monitor both training and validation metrics. Use early stopping to avoid overfitting. Save checkpoints so you can resume training. Use mixed precision to speed up training on modern GPUs. Finally, test on a holdout set for realistic performance estimates.
Common applications of CNN architecture
CNNs power many real-world image tasks today. They work for image classification and object detection. They also do semantic and instance segmentation. Face recognition, medical imaging, and autonomous driving use CNNs heavily. Even video tasks use CNNs per frame or with temporal modules. In industrial settings, lightweight CNNs run on edge devices. In creative fields, CNNs help style transfer and image editing. The right architecture depends on latency and accuracy needs. Engineers often combine CNNs with other modules for full systems.
Visualizing and understanding CNNs
Understanding a cnn architecture helps debug and trust models. Feature visualization shows what filters respond to. Activation maps highlight image regions that matter for predictions. Grad-CAM and saliency methods expose important pixels. These tools help find dataset bias or spurious cues. Visualizing filters often reveals edge detectors in early layers. In later layers, visualizations reveal complex shapes. Use these insights to improve data or architecture. Explainability is crucial for high-stakes applications like healthcare.
Performance trade-offs and deployment
When deploying a cnn architecture, trade-offs matter. Faster models sacrifice some accuracy. Smaller models save memory and run on mobile devices. Techniques like pruning and quantization shrink models. Knowledge distillation transfers knowledge to smaller students. Use hardware-aware design for GPUs, TPUs, or mobile chips. Measure latency, throughput, and energy for your target device. Also consider model updates and monitoring in production. Automated tools can convert models to optimized formats. Practical deployment requires both model and system engineering.
Future trends in CNN architecture
CNNs keep evolving. Hybrid models now combine convolution and attention. Transformers adapted to vision challenge pure CNN dominance. Efficient architectures keep improving for edge devices. Self-supervised learning reduces reliance on labels. Neural architecture search automates design choices. Better explainability methods are under development. For many tasks, a blend of CNNs and other structures gives the best results. Learning to use these trends will keep your skills fresh and useful.
Real examples and personal notes
I once built a small cnn architecture for a hobby project. The goal was to detect plant leaves with disease. I started with a pretrained backbone and fine-tuned it. Data augmentation helped a lot. I added early stopping and used Grad-CAM to inspect failures. That visual check found a labeling issue in the dataset. After fixes, accuracy rose noticeably. Small design changes made a big practical impact. Real projects often need these iterative fixes. Practical work is where architecture choices meet messy data.
Conclusion and next steps
You now have a practical map of cnn architecture basics. You saw layers, regularization, and design decisions. You also learned how to train and deploy these models. If you want hands-on practice, start with a small dataset. Try transfer learning with a pretrained backbone first. Visualize model outputs to build trust. Keep notes on what changes help and why. If you need a specific recipe, I can write one step-by-step for your task. Share your project details, and we will design a fitting cnn architecture together.
Frequently Asked Questions
1. What is the difference between a convolution and a fully connected layer?
A convolution uses small filters to scan images and produce feature maps. It shares weights across positions. This makes convolution efficient for images. A fully connected layer connects every input to every output neuron. Fully connected layers lose spatial layout information. They are often used near the end of a cnn architecture for classification. Convolutions keep spatial structure, which helps with visual tasks. Because of this, convolutional layers dominate CNNs for image work.
2. How many layers should my CNN have?
There is no fixed number of layers for a cnn architecture. Simple tasks can work with a few layers. Harder tasks often need deeper networks. Use a small model first for faster experiments. If accuracy stalls, add depth or skip connections. Residual connections let very deep nets train better. Always balance depth with available data and compute. Monitor validation metrics to decide when to stop adding layers.
3. When should I use transfer learning?
Use transfer learning when your dataset is small or similar to common datasets. Pretrained backbones save time and improve results. Fine-tuning often beats training from scratch for limited data. If your problem is very different, consider more extensive fine-tuning. Transfer learning is a practical, widely used approach in cnn architecture work.
4. What role does Batch Normalization play?
Batch Normalization stabilizes and speeds up training in a cnn architecture. It normalizes activations within each mini-batch. This reduces internal covariate shift during training. The result is faster convergence and often better accuracy. It also enables higher learning rates. Use BatchNorm after convolution and before activation in many models. For small batch sizes, consider GroupNorm or LayerNorm instead.
5. Can CNNs work on non-image data?
Yes. While CNNs excel at images, they apply to other structured data. Time series, audio spectrograms, and text embeddings can use convolutional layers. The idea of local patterns and weight sharing fits many domains. For each domain, adapt input shapes and preprocessing. The core concepts of cnn architecture still provide value beyond images.
6. Are CNNs obsolete because of transformers?
Transformers changed vision research, but CNNs remain very relevant. They are efficient and effective, especially on limited data or tight compute budgets. Hybrid models that combine convolution and attention often give the best practical results. For many production systems, a well-designed cnn architecture is still the best choice. The right tool depends on your task, data, and constraints.